一旦ZooKeeper集合启动,它将等待客户端连接。 客户端将连接到ZooKeeper集合中的一个节点。 它可以是领导者或跟随者节点。 一旦客户端被连接,该节点向该特定客户端分配会话ID并向该客户端发送确认。 如果客户端没有得到确认,它只是尝试连接ZooKeeper集合中的另一个节点。 一旦连接到节点,客户端将以定期间隔向节点发送心跳,以确保连接不会丢失。
如果客户端想要读取特定的znode,会向具有znode路径的节点发送读取请求,并且节点通过从其自己的数据库获取它来返回所请求的znode 。 为此,在ZooKeeper集合中读取速度快。
如果客户端想要将数据存储在ZooKeeper集合中,它会将znode路径和数据发送到服务器。 连接的服务器将该请求转发给领导者,然后领导者将向所有的跟随者重新发出写入请求。 如果只有大多数节点成功响应,则写请求将成功,并且成功的返回码将被发送到客户端。 否则,写入请求将失败。 严格的大多数节点被称为 Quorum 。
ZooKeeper合奏中的节点
让我们分析在ZooKeeper集合中拥有不同数量的节点的效果。
如果我们有单个节点,则当该节点失败时,ZooKeeper集合失败。 它有助于“单点故障",并且不推荐在生产环境中使用。
如果我们有两个节点和一个节点失败,我们没有多数,因为两个中的一个不是多数。
如果我们有三个节点和一个节点失败,我们有大多数,所以,这是最低要求。 ZooKeeper集合在实际生产环境中必须至少有三个节点。
如果我们有四个节点和两个节点失败,它再次失败,它类似于有三个节点。 额外节点不用于任何目的,因此,最好添加奇数的节点,例如3,5,7。
我们知道写入过程比ZooKeeper集合中的读取过程昂贵,因为所有节点都需要在其数据库中写入相同的数据。 因此,与具有用于平衡环境的大量节点相比,具有更少数量的节点(3,5或7)是更好的。
下图描述了ZooKeeper WorkFlow,后面的表解释了它的不同组件。
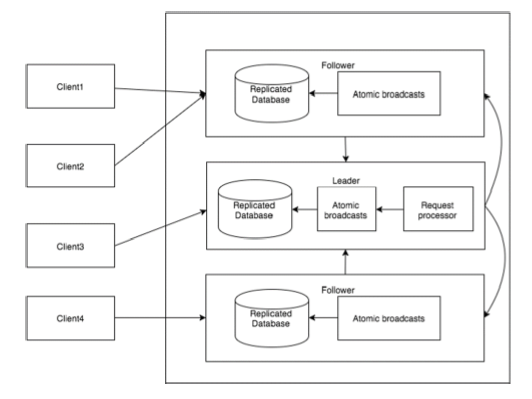
| 零件 | 描述 |
|---|---|
| Write | 写过程由领导节点处理。 领导者将写请求转发到所有znode,并等待znode的答案。 如果znode的一半回复,则写入过程完成。 |
| Read | 读取由特定连接的znode在内部执行,因此不需要与群集交互。 |
| 复制数据库 | 它用于在zookeeper中存储数据。 每个znode都有自己的数据库,每个znode在一致性的帮助下每次都有相同的数据。 |
| Leader | Leader是负责处理写入请求的Znode。 |
| Follower | 关注者从客户端接收写请求并将它们转发到领导znode。 |
| 请求处理器 | 只存在于领导节点。 它管理来自从节点的写请求。 |
| 原子广播 | 负责将从领导节点到从节点的变化广播。 |